Cracking the 'Impossible Triangle' with RETNET
- 5 Dec, 2023
- Deep Learning

Recurrent Neural Networks (RNNs) and Transformers represent two influential paradigms in the realm of deep learning architectures. RNNs, tailored for sequential data, process information step by step, maintaining a hidden state capturing past inputs. On the other hand, Transformers, propelled by their attention mechanism, excel in parallel processing, proving effective in tasks like natural language processing and image recognition.
However, both models grapple with inherent challenges. RNNs, due to their sequential nature, face hurdles in training parallelism and can be computationally expensive during inference. Transformers, while proficient in parallelization, encounter difficulties in handling long-range dependencies efficiently.
The Impossible Triangle Dilemma
Visualize an "impossible triangle," a conceptual challenge highlighting the difficulty of achieving three crucial aspects simultaneously: training parallelism, low-cost inference, and strong overall performance. Improving one often comes at the expense of the others, creating a complex dilemma for model architects.
RETNET Emerges: A Unified Framework
Enter RETNET, a groundbreaking architecture that ingeniously merges the strengths of RNNs and Transformers, transcending the limitations of the "impossible triangle."
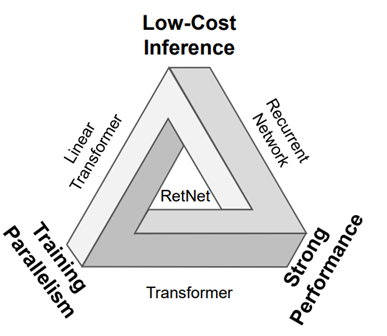
Three Processing Paradigms of RETNET
Parallel Training
RETNET leverages parallel training, optimizing the utilization of GPU devices. This approach ensures efficient and swift model learning, a departure from the sequential constraints of traditional RNNs.
Recurrent Inference
A key innovation lies in RETNET's recurrent inference paradigm, achieving O(1) inference. This translates to reduced deployment costs and latency, presenting a significant advancement over the computational heaviness often associated with sequential models.
Chunk-wise Recurrent Representation
RETNET introduces a novel approach to long-sequence modeling by combining parallel and recurrent encoding. This chunk-wise representation efficiently balances local and global context, addressing the challenges faced by pure sequential or fully parallel models.
Overcoming Inference Cost and Memory Complexity
While RNNs exhibit constant inference cost (O(1)) but linear memory complexity, and Transformers face linear scaling in both inference cost (O(N)) and memory complexity (O(N^2)), RETNET strikes a balance. It deploys a multi-scale retention mechanism to substitute multi-head attention, addressing self-attention's challenges. The tweaked self-attention module ensures RETNET avoids the inference cost and memory complexity pitfalls inherent in traditional Transformer architectures.
In Conclusion: The Promise of RETNET
As we dissect RETNET's architecture and innovative features, it becomes evident that this model is not just an incremental improvement but a transformative leap forward. By seamlessly integrating the strengths of RNNs and Transformers, RETNET offers a glimpse into the future of deep learning architectures. It not only addresses the challenges posed by the "impossible triangle" but also sets the stage for further advancements in the realm of sequential data processing. RETNET, with its elegant design and promising outcomes, marks a significant milestone in the evolution of neural network architectures.
Powered by Froala Editor