Mastering Natural Language Understanding with ULMFiT Fine-Tuning
- 5 Oct, 2023
- Natural Language Processing
Introduction
In the rapidly evolving field of Natural Language Processing (NLP), the quest for more effective models has led to groundbreaking innovations. One such innovation is ULMFiT, which stands for Universal Language Model Fine-Tuning. This revolutionary approach has redefined the way we approach language-related tasks, making it possible to achieve remarkable results even with limited labeled data.
This method dramatically improves over previous approaches to text classification, and the code and pre-trained models allow anyone to leverage this new approach to better solve problems such as:
Finding documents relevant to a legal case;
Identifying spam, bots, and offensive comments;
Classifying positive and negative reviews of a product;
Grouping articles by political orientation etc
What is Fine-Tuning?
Fine-tuning, in the context of deep learning, is the process of taking a pre-trained model and adapting it to perform a specific task. Imagine you have a skilled generalist worker (the pre-trained model) and you want them to excel in a specialized job (the specific task). Instead of starting from scratch, you tweak their skills to match the new job requirements. This approach is efficient and effective, especially when data is scarce. It also saves you from the hassles of training your data which could also decrease your cost of production
What is ULMFiT?
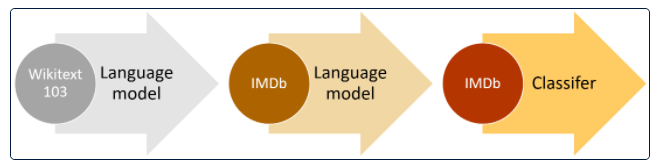
ULMFiT, or Universal Language Model Fine-Tuning, is a game-changing technique in NLP. At its core, ULMFiT takes a pre-trained language model and refines it for a specific downstream task. The beauty of ULMFiT lies in its ability to work well even with limited labeled data. This method is developed by Jeremy Howard and Sebastian Ruder in 2018, in this Research Paper, ULMFiT uses a regular LSTM (without any attention short-cut connection or any other complex addition) which is the state-of-the-art language model architecture (AWD-LSTM, Merity et al., 2017a)
How Does ULMFiT Work?
ULMFiT operates in a series of well-defined steps, each contributing to its success:
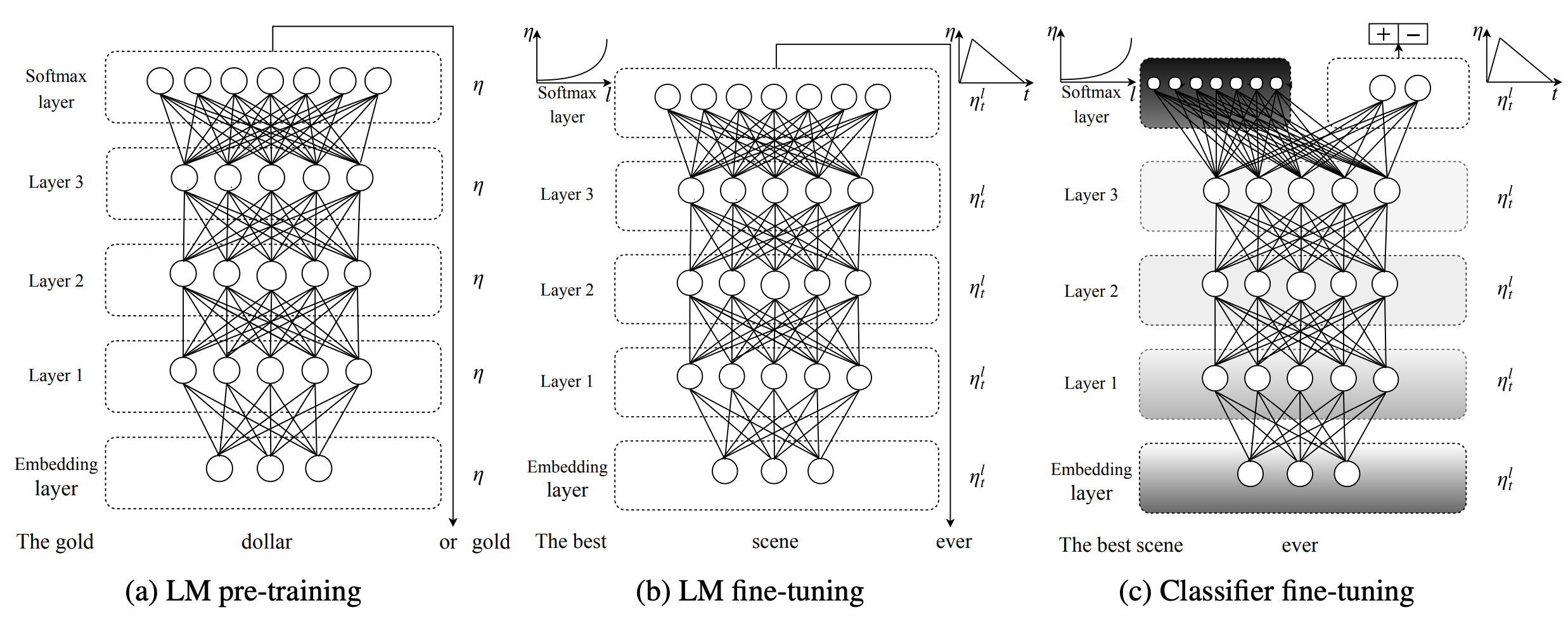
a) General-domain LM Pretraining: Initially, a pre-trained model learns the general features of language using a vast dataset. It captures everything from sentence structures to sentiment, thanks to unsupervised learning.
b) Target Task LM Fine-Tuning: Once the model understands the general aspects of language, it's fine-tuned using task-specific data. This phase involves semi-supervised learning, allowing the model to adapt to the specific language characteristics of the target task. To carry out fine-tuning at this step we used Discriminative fine-tuning (‘Discr’) in this we only fine tuned some layers of the network and instead of using the same learning rate for all layers of the model, discriminative fine-tuning allows us to tune each layer with different learning rates.
c) Target Task Classifier Fine-Tuning: This is where the model becomes task-specific. Classifier layers are added, and their parameters are trained from scratch. The key innovation here is the concatenation of hidden states, enhancing the model's ability to grasp context.
How is ULMFiT Better than Other Models?
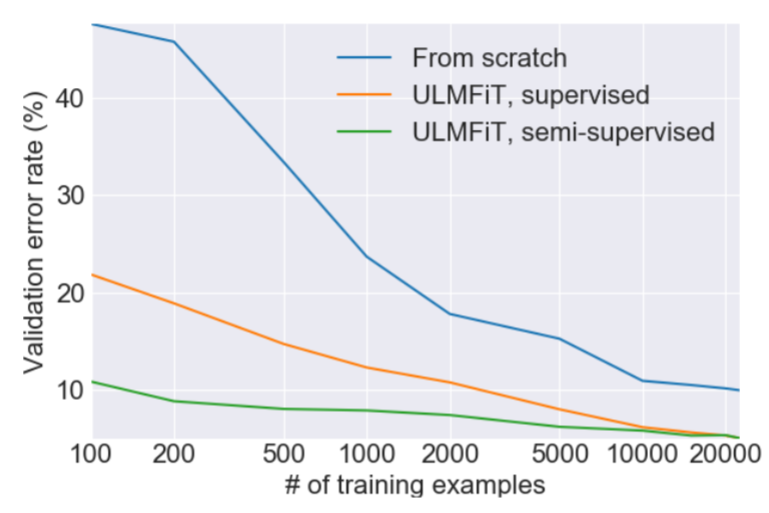
ULMFiT's superiority lies in its ability to perform exceptionally well even with limited labeled data. It bridges the gap between generic pre-trained models and task-specific requirements. This approach significantly reduces the data and computational resources needed, making it a game-changer in real-world applications.
Future and Limitations
The future of ULMFiT is bright. As NLP tasks continue to evolve, ULMFiT's adaptability and efficiency will be invaluable. However, it's not without limitations. ULMFiT's effectiveness can vary depending on the specific task and dataset. Moreover, it may not outperform fully supervised models when ample labeled data is available. Researchers are actively addressing these challenges, and we can expect further refinements in the coming years.
In conclusion, ULMFiT has revolutionized NLP by demonstrating the power of fine-tuning pre-trained models. Its ability to work with limited data and adapt to diverse language tasks makes it a compelling choice for a wide range of applications. While it may have its limitations, ULMFiT's contribution to the field is undeniable, and its future looks promising.
Powered by Froala Editor