CoDi: A Revolutionary Model Unleashing the Power of Multimodal Generation
- 10 Aug, 2023
- Natural Language Processing
Introduction
Get ready to witness the dawn of a groundbreaking generative model! Developed by Microsoft, CoDi is here to redefine the possibilities of artificial intelligence. CoDi, short for Composable Diffusion, breaks free from the limitations of traditional AI systems. It introduces a new era of generative models that can create various combinations of output modalities, such as language, images, videos, and audio, from different combinations of input modalities. Let's deep dive into this interesting concept.
Understanding Modality
In the context of CoDi, a modality refers to a way of representing information. It's like having different "modes" through which data can be expressed. For example, language is a modality that uses words and sentences to convey meaning. Images, on the other hand, use visual representations, while videos combine moving images with sound. Audio refers to the sounds we hear, like music or spoken words. Each modality provides a unique perspective and way of communication.
Introducing Multimodality
Now, let's explore the concept of multimodality. Simply put, multimodality is the ability to combine different modalities together. CoDi excels in this area, allowing the generation of multiple modalities simultaneously. Imagine this: with CoDi, you can generate a story that includes written words, captivating images, accompanying videos, and even background sound effects. This blending of modalities creates a more immersive and engaging experience for the audience.
Unlocking the Potential of Multimodal Generation
CoDi's ability to generate various combinations of modalities marks a significant breakthrough. Unlike previous AI systems that were limited to specific modalities or could only generate one at a time, CoDi empowers us to create outputs that simultaneously incorporate language, images, videos, and audio. This opens up a world of possibilities for creative storytelling, interactive presentations, and seamless human-computer interactions. Let's say you want to create a travel guide. With CoDi, you can generate a visually stunning webpage that includes written descriptions, beautiful images, informative videos, and even audio snippets of local sounds. It's like bringing the destination to life!
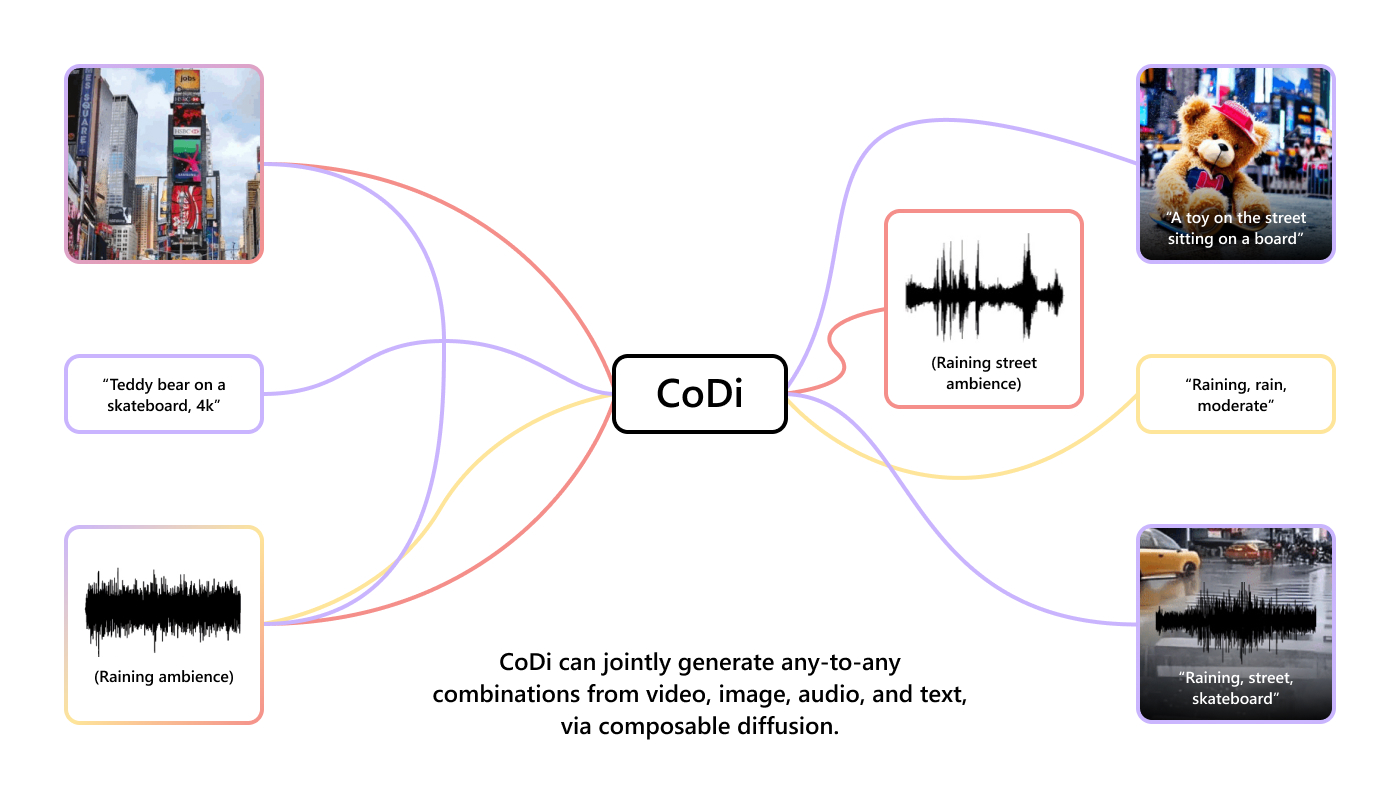
Now, let's take a closer look at how CoDi is trained. The creators follow a meticulous process, building individual diffusion models for each modality, such as text, images, videos, and audio. These models are aligned through prompt encoders, which help project inputs into a shared feature space. A remarkable technique called latent alignment allows different diffusion models to work together, facilitating joint multimodal generation. It's as if these models collaborate and exchange information, like musicians playing different instruments in a symphony, resulting in a harmonious output.
Evaluating CoDi's Power
The research showcases CoDi's remarkable prowess through evaluation results across various modalities and combinations. CoDi delivers impressive performance in tasks like image captioning, audio generation, and video captioning, standing shoulder-to-shoulder with the best in the field. For example, CoDi can generate accurate and engaging captions for images, create realistic sounds, and even provide descriptive narratives for videos. The generated outputs demonstrate CoDi's ability to understand and combine modalities effectively, resulting in high-quality content.
CoDi: A Leap Forward in Generative Models
In conclusion, CoDi represents a monumental leap forward in the world of generative models. Its comprehensive and versatile approach to multimodal generation sets a new standard in the field. The results obtained thus far pave the way for engaging and holistic human-computer interactions, while opening up avenues for further research in generative AI. With CoDi, we can now create captivating stories, interactive presentations, and immersive experiences that blend language, images, videos, and audio seamlessly. Get ready to witness the future unfold before your eyes with CoDi, the game-changer in artificial intelligence.
Powered by Froala Editor